
IA générative : ces algorithmes qui révolutionnent la création de contenus
Cet article est issu de L'Édition n°25.
Depuis le lancement de ChatGPT en 2022, l’intelligence artificielle (IA) générative ne cesse de trouver de nouvelles applications dans divers domaines de notre quotidien. Mais qu’est-ce que l’IA générative ? Comment fonctionne-t-elle ? Et quels sont ses apports et ses limites ? Focus sur une technologie devenue omniprésente.
« Au cours des dernières décennies, l'intelligence artificielle (IA) a connu des avancées spectaculaires, et parmi ses branches les plus prometteuses se trouve l'IA générative. Contrairement aux algorithmes traditionnels, celle-ci est capable de créer de nouvelles données jamais observées auparavant. Cette capacité ouvre des horizons inédits dans des domaines très variés tels que la rédaction… »
Si vous n’aviez pas encore eu l’occasion de tester les capacités de l’IA générative, en voici une démonstration. Le paragraphe précédent n’a pas été rédigé par un être humain mais par ChatGPT, l’agent conversationnel (ou chatbot) de la société OpenAI. Dévoilé en novembre 2022, ce système a fait l’effet d’une révolution auprès du grand public. Deux mois après son lancement, il dénombrait déjà plus de 100 millions d’utilisateurs et utilisatrices. Aujourd’hui, ChatGPT demeure l’IA générative la plus connue et la plus utilisée, avec quelque 1,8 milliard de visites mensuelles sur la plateforme dédiée.
L’Université Paris-Saclay traverse aussi cette révolution de l’IA générative. Mais comment cela s’y illustre-t-il ? Cette question a été abordée lors de la journée organisée le 5 juin dernier sur le plateau de Saclay par la Direction de l'innovation pédagogique (DIP) et la Graduate School Métiers de la recherche et de l’enseignement supérieur (GS MRES), avec le soutien de l'Institut DATAIA, l’institut d’intelligence artificielle de l’Université Paris-Saclay. « L’objectif était de démystifier l’IA générative et d’offrir un panorama pluridisciplinaire de l’utilisation des outils comme ChatGPT à l’université », explique Serge Pajak, chercheur au laboratoire Réseaux, innovation territoires mondialisation (RITM - Univ. Paris-Saclay) et chargé de mission IA générative à l’université. « ChatGPT est devenu tellement populaire que de nombreuses étudiantes et étudiants l’utilisent déjà. Ceci impose en quelque sorte à la communauté enseignante de se positionner par rapport à cette technologie pour en orienter les bonnes pratiques. » À l’Université Paris-Saclay, des enseignantes et enseignants se sont déjà emparés du sujet, en posant par exemple au chatbot une question de cours et en commentant sa réponse avec les étudiantes et étudiants. « C’est une méthode intéressante car très efficace pour intégrer l’IA dans l’enseignement et la mobiliser de manière critique, en discutant de la qualité de son contenu. »
Cartographier les usages et les compétences en IA générative au sein de l’université, c’est justement la tâche principale du chargé de mission. Avec la DIP et la GS MRES, « nous travaillons aussi à construire un accompagnement à l’utilisation de ces outils. L’idée est notamment de proposer des formations sous forme d’acculturation avec une approche assez pratique, ainsi qu’une sensibilisation sur les mésusages potentiels de cette technologie. » Parmi ces mésusages, on compte par exemple le fait de laisser à ChatGPT le choix de valider, ou non, un projet après l’analyse de son dossier. Or « sa mécanique interne n’est pas du tout adaptée à cela », assure Serge Pajak. Pour comprendre pourquoi, il faut plonger au cœur même de l’IA générative, ou plutôt des multiples systèmes que recouvre ce terme.
IA générative : un terme unique pour des systèmes très différents
Bien que l’IA générative semble avoir émergé très récemment, elle est le fruit de plusieurs décennies d’innovations dans le domaine du machine learning (apprentissage automatique). Des innovations qui se sont accélérées au cours des dix dernières années, donnant naissance à l’IA générative telle qu’on la connaît. « Avant toute chose, il faut souligner que ce terme est très commercial. C’est un mot-clé utilisé comme moteur de communication mais il est trop flou sur le plan scientifique », prévient Vincent Guigue, enseignant-chercheur rattaché au laboratoire Mathématique et informatique appliquées (MIA – Univ. Paris-Saclay/AgroParisTech/INRAE).
En pratique, l’IA générative fait bien appel à un concept scientifique, à savoir des systèmes informatiques capables de générer des données. « Le problème est qu’on regroupe sous ce chapeau des architectures très différentes les unes des autres. » Le terme désigne aussi bien ChatGPT, conçu pour générer du texte, que MidJourney, utilisé pour créer des images, GitHub Copilot, destiné à fournir du code informatique, ou encore AlphaFold, spécialisé dans la modélisation des protéines. « Techniquement parlant, ces modèles ne reposent pas du tout sur les mêmes composants, ni les mêmes modalités de données », appuie l’enseignant-chercheur.
Si leurs architectures diffèrent, les modèles d’IA générative partagent une base commune : celle du deep learning (apprentissage profond). Il s’agit d’opérateurs mathématiques très complexes constitués d’unités élémentaires : les neurones artificiels. Ces derniers sont regroupés en réseaux constitués de dizaines voire de centaines de couches de neurones interconnectés qui vont analyser les données fournies. Hyper-flexibles, ces architectures sont adaptables à des types de données très variés - textes, images, sons, données numériques, etc. - pour des applications tout aussi diverses. Le traitement automatique de la langue (en anglais Natural Language Processing, NLP) est l’une d’entre elles.
En intelligence artificielle, « traiter l’information textuelle est une tâche extrêmement compliquée », explique Vincent Guigue. « Il existe des centaines et des centaines de milliers de mots. Sans compter les fautes d’orthographe qu’on fait au quotidien. S’attaquer aux données textuelles est donc difficile. » C’est pourtant bien ce que font aujourd’hui ChatGPT et d’autres outils, tels que Claude, développé par Anthropic, ou LaMDA, créé par Google.
Les modèles de langue, de « fantastiques outils » pour traiter le texte
Leur secret réside dans les modèles de langue, des architectures spécifiquement conçues pour traiter du texte. « L’intérêt de ces modèles est de mieux représenter l’information textuelle en réalisant une projection des mots dans un espace vectoriel continu. Chacun des mots devient un point dans l’espace. » Et la position de chacun de ces points est d’une importance cruciale. Plus les points sont proches, plus leur signification est similaire. Cet espace présente par ailleurs des régularités : en réalisant des translations, on passe ainsi d’un féminin à un masculin, d’un singulier à un pluriel, etc. Transféré dans un tel espace, un texte devient alors plus facile à analyser et à comprendre.
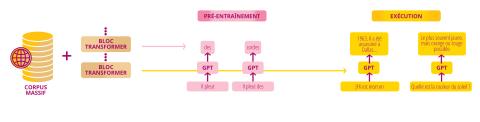
En réalité, ce ne sont pas tout à fait les mots qui sont analysés. Les modèles pratiquent ce qu’on appelle la tokénisation : le texte est divisé en petites entités appelées tokens (ou jetons) qui sont des mots, des syllabes ou des suites de caractères. Cette découpe aide les modèles à réduire la variabilité linguistique, à s’adapter aux fautes d’orthographe ou à modéliser plusieurs langues en conservant un vocabulaire limité. Mais pour bien traiter les textes qui leur sont confiés, les algorithmes doivent d’abord s’entraîner et ce, sur une grande quantité de données. ChatGPT, par exemple, repose sur un modèle Transformer, plus exactement un GPT (Generative Pre-trained Transformer) qui est entraîné à prédire le token suivant. Sa mission consiste donc à compléter une séquence, token par token, avec la suite la plus probable possible, en fonction du contexte précédent.

À partir de cette capacité d’analyse, découlent diverses applications. « Les modèles de langue sont de fantastiques outils pour classer des mots, extraire des connaissances à partir de documents ou synthétiser des textes », confirme Vincent Guigue. Là où l’arrivée de ChatGPT marque une révolution, c’est que le chatbot va bien au-delà de ça. « Jusque-là, ces modèles étaient des outils intermédiaires pour être meilleur sur les tâches de traitement de la langue. Mais le fait qu’un modèle soit capable de générer des textes basés sur des connaissances et de répondre pertinemment à des questions complexes, c’est totalement nouveau. »
Des sorties optimisées grâce à un apprentissage par renforcement
La création d’OpenAI repose sur un grand modèle de langue (en anglais Large Language Model, LLM). Autrement dit, un réseau de neurones bien plus gros et entraîné sur bien plus de données. À son lancement, le chatbot fonctionne à l’aide d’une version de GPT-3 affichant une taille de 175 milliards de paramètres. À titre de comparaison, « le modèle Transformer à la mode en 2017 faisait 100 millions de paramètres, ce qui était déjà énorme », précise Vincent Guigue. Quant au volume qui a servi à l’entraîner, il s’agit d’un corpus massif de plusieurs téraoctets (To) de données comprenant des centaines de milliers d’articles, livres et autres textes issus du web. « On estime que les contenus Wikipédia constituent à peine 3 % de l’archive utilisée pour l’apprentissage de ChatGPT. »
C’est sur ce corpus massif que le modèle s’est entraîné à prédire le mot suivant afin de modéliser la langue et mémoriser des connaissances. Sauf qu’OpenAI n’en est pas restée là. Grâce à des données supplémentaires plus qualitatives, la société a aussi entraîné le GPT au jeu de questions-réponses et à d’autres tâches de raisonnement. Enfin, « il y a eu une dernière étape d’apprentissage par renforcement avec un être humain dans la boucle : une question est posée au système qui génère dix réponses. Ensuite, l’intervenant humain note les réponses pour diriger le système vers les plus pertinentes. Avec une telle étape, on gagne beaucoup de qualité dans les réponses. On peut aussi censurer les sujets sensibles », détaille l’enseignant-chercheur. Avant ChatGPT, ce type d’apprentissage n’avait encore jamais été utilisé pour optimiser les sorties d’un modèle.
C’est grâce à cet apprentissage particulier que le chatbot est aujourd’hui capable de répondre, dans un langage étonnamment naturel, aux multitudes de requêtes (ou prompts) qui lui sont soumises. Qu’il s’agisse d’écrire un discours ou de dénicher une recette de cuisine, ChatGPT suit toujours le même processus : identifier tour par tour le mot suivant le plus probable. « Pour lui, la réponse est une succession de mots vraisemblables qui viennent à la suite de la phrase donnée en entrée. » Voilà pourquoi, comme évoqué plus haut, demander son avis à ce type de système sur un dossier ou un devoir est inadapté.
Le traitement du langage n’est pas la seule application à connaître une évolution spectaculaire grâce aux réseaux de neurones. C’est aussi le cas de la création d’images, dont on constate les progrès avec des systèmes comme MidJourney, qui génère aujourd’hui des images d’un réalisme bluffant. « Le domaine du machine learning ne va pas du tout à la même vitesse que les autres sciences. Quand on regarde à postériori ce qui s’est passé au cours des dix dernières années, c’est un TGV. Tous les enseignants comme moi ont dû refaire leurs cours plus de cinq fois, sinon on racontait des choses qui n’avaient plus de sens », témoigne Vincent Guigue.
Des modèles qui font des erreurs
Aussi performants soient-ils devenus, les modèles génératifs conservent des limites. ChatGPT et les autres systèmes similaires « n’ont pas de notion de ce qui est bon ou mauvais dans leur réponse. Ils ont une notion de ce qui est vraisemblable ou non », pointe Vincent Guigue. Ils sont donc tout à fait capables de générer des erreurs, des réponses statistiquement bonnes mais factuellement fausses. Ces « hallucinations » sont notamment fréquentes lorsque l’on interroge la machine sur des connaissances rares ou postérieures à ses données d'entraînement. Or, « les modèles ne savent pas dire qu’ils ne savent pas. Ils sont très confiants dans leurs bonnes réponses comme dans leurs erreurs. »
Une autre limite essentielle des modèles est leur manque de prédictibilité et d’explicabilité. Pourquoi ce modèle a-t-il fourni cette réponse plutôt qu’une autre ? « On est aujourd’hui incapable d’expliquer le processus de décision de ces modèles parce qu’il y a trop de paramètres combinatoires. » Des études ont montré que certains prompts insolites tels que demander à la machine de « respirer profondément » améliorent la qualité de ses réponses. Sans que l’on ne sache pourquoi.
« Il y a plein d’applications où les limites des modèles ne sont pas acceptables. Si l’on dit qu’un modèle est bon à 97 %, cela semble bien. Mais un véhicule autonome bon à 99 % est une catastrophe », illustre l’enseignant-chercheur, prenant en exemple l’accident mortel survenu en 2018 entre un véhicule Uber et une piétonne. « Au lendemain de l’accident, on savait tout sur ce qu’il s’était passé, on a une capacité d’explication a posteriori. Le problème est qu’on n’avait pas su prédire que l’algorithme allait se tromper sous certaines conditions. »
La médecine est un autre domaine où l’IA générative a récemment fait son entrée. « C’est très bien que les médecins bénéficient d’une aide au diagnostic. Les algorithmes peuvent pointer des éléments qui leur ont échappé et peuvent avoir du sens », juge Vincent Guigue. « Mais ces choses peuvent aussi ne pas avoir de sens du tout. C’est pour cela qu’il est impératif que les décisions restent humaines. Ces systèmes sont de très bons assistants, mais pas de très bons remplaçants. »
Références :
- La journée de conférences du 5 juin 2024 : https://parissaclay.mediasite.com/Mediasite/Channel/iagenerative/
IA générative et éthique : le défi d’encadrer une technologie en pleine émergence
L’essor de l’IA générative ne vient pas sans défis, ni risques. Cette technologie révolutionnaire soulève de nombreuses questions éthiques et juridiques, liées à sa conception, ses usages ou encore son impact sociétal. À l’échelle mondiale, diverses actions tentent de la réglementer mais se heurtent au défi d’encadrer une technologie encore en pleine émergence.
C’est une loi historique qui est entrée en vigueur en août 2024 dans l’Union européenne (UE). Nommée IA Act, elle vise à jeter les bases de la réglementation de l’intelligence artificielle (IA) au sein de l’UE. Cela faisait trois ans que les instances européennes planchaient sur ce projet de législation, qui n’a pas manqué de susciter le débat. Et pour cause, à l’échelle mondiale, l’UE est la première à se doter d’une loi pour répondre à l’essor de l’IA, y compris celui de l’IA générative.
Si l’IA soulève, de façon générale, de nombreuses questions éthiques et juridiques, les systèmes d’IA générative suscitent leurs propres interrogations. Les grands modèles de langue (LLM), comme celui utilisé par ChatGPT, sont capables de générer ce qu’on appelle du langage toxique. Il s’agit d’insultes, de discours de haine, d’incitations à la violence, d’énoncés offensants ou irrespectueux. Certains contenus sont aussi susceptibles de refléter des biais, tels que des stéréotypes racistes ou discriminatoires.
Pour réduire ce type de sorties, les constructeurs mettent en place des filtres ou des contrôles via l’intervention de modérateurs humains durant la phase d’apprentissage des modèles. Or, ce processus n’est aujourd’hui ni transparent, ni vérifié. Il n’est pas non plus infaillible. « Ces filtres et contrôles ne suppriment pas le langage toxique. Ils le rendent juste moins probable », confirme Alexei Grinbaum, directeur de recherche au CEA Paris-Saclay et président du Comité opérationnel pilote d'éthique du numérique du CEA. À l’inverse, cette modération peut aussi conduire à un excès de contrôle.
L’origine et la qualité des données utilisées pour l’apprentissage des modèles constituent une autre source d’interrogations. « Nous avons ici le premier niveau de l’éthique de l’IA générative. C’est tout ce qui concerne l’aspect technique : comment les modèles sont-ils conçus et quels usages en fait-on ? », détaille le physicien du CEA. « Mais nous avons aussi un autre type de considérations éthiques lié aux effets à long terme de cette technologie sur la société et les êtres humains. Par exemple, comment les modèles changent-ils les pratiques professionnelles ? »
Les spécialistes de l’éthique du numérique n’ont pas attendu le lancement de ChatGPT en novembre 2022 pour se questionner sur les enjeux de ces systèmes. Dès 2021, le Comité national pilote d'éthique du numérique (CNPEN), placé sous l’égide du Comité consultatif national d’éthique (CCNE) et mis en place deux ans plus tôt, publie un premier avis sur les agents conversationnels. « Nous y parlons des modèles de langue Transformer et de leur impact sur la société. À l’époque, on prévoyait déjà l’ampleur et la gravité des questions que cela allait poser », précise Alexei Grinbaum, membre du CNPEN et co-rapporteur de cet avis. En 2023, un second avis sort, avec une trentaine de préconisations pour la conception, la recherche et la gouvernance des systèmes d’IA générative. Le CNPEN - dont la mission prend fin en 2024 pour laisser place à une structure permanente - « a été le premier à l’échelle nationale et internationale à se prononcer sur ces questions ».
Un cadre réglementaire « nécessaire »
Les enjeux liés à ces systèmes sont tels qu’il est « nécessaire d’établir un cadre réglementaire », estime Alexei Grinbaum. C’est dans ce but que l’Union européenne adopte l’IA Act, dont les mesures commenceront progressivement à s’appliquer à partir de 2025. Parmi les dispositions les plus importantes, cette législation introduit la notion de systèmes d’IA à haut risque lorsqu’utilisés dans des domaines sensibles comme l’éducation, l’emploi ou l’octroi de crédits bancaires. « Cela signifie que tous les systèmes fonctionnant dans les secteurs concernés sont soumis à des obligations et des certifications », détaille l’enseignant en éthique des sciences. De même, le texte établit une classification des modèles d’IA à usage général, en imposant diverses obligations en fonction du risque qui leur est associé.
Dans cette loi, « on retrouve tous les principes qui existaient déjà pour l’IA en 2019 : la transparence, l’explicabilité, la robustesse, la sécurité. Ce qui me semble très intéressant, c’est qu’elle instaure un principe éthique nouveau : celui du maintien des distinctions. » En effet, la législation exige qu’un contenu généré par un modèle soit distinguable d’un contenu créé par un être humain. « C’est un principe fondamental que nous avions évoqué avec le CNPEN. Mais scientifiquement, c’est une chose difficile à mettre en œuvre pour certains contenus. » Des marqueurs tels que des filigranes (ou watermarks) montrent leur efficacité pour identifier des images ou des vidéos générées par IA. Avec le texte, en revanche, la tâche s’avère bien plus complexe. « Il y a dans cette loi des obligations pour lesquelles nous n’avons actuellement pas de solutions scientifiques », reconnaît le spécialiste.
Cet exemple, parmi d’autres, illustre le défi que représente « l’opérationnalisation » - la mise en application - des principes édictés par la législation. Il souligne aussi l’importance d’établir un dialogue entre les acteurs et actrices techniques du secteur et les instances réglementaires, selon Alexei Grinbaum. Ceci est d’autant plus crucial que l’IA générative est une technologie en pleine émergence et qui évolue très vite : « Huit mois équivaut à un siècle dans le domaine de l’intelligence artificielle. L’avènement de ces technologies est bien plus rapide que le processus législatif. » Encadrer l’IA par une loi est-il alors la meilleure solution ? « Le problème est qu’il faut faire une loi qui soit suffisamment souple pour évoluer très vite et ne pas la regretter d’ici cinq à dix ans. Ce qui, à mon sens, n’est pas complètement le cas avec l’IA Act. » En mai 2025, le Bureau de l’IA, créé par la Commission européenne, doit publier les codes de pratique pour faire appliquer le règlement européen. « C’est là que nous verrons la portée concrète et pratique des articles très politiques de la loi », prédit Alexei Grinbaum.
Ailleurs aussi, des initiatives similaires voient le jour. En 2023, la Chine, de même que les États-Unis, se dotent de nouvelles réglementations pour encadrer le développement et l'utilisation de l’IA, y compris l’IA générative. Dans l’espoir de rattraper l’évolution des dernières années. Mais la technologie aura vraisemblablement toujours des coups d’avance. « Avec cette technologie qui diffuse dans tous les secteurs, il n’est pas possible de tout imaginer. Il est certain que dans vingt ans, il y aura tout un tas de nouvelles questions auxquelles nous n’aurons pas pensé », prédit le physicien du CEA.
Références :

Cet article est issu de L'Édition n°25.
L'intégralité du journal est à découvrir ici en version numérique.
Pour découvrir d'autres articles et sujets, abonnez-vous au journal L'Édition et recevez les prochains numéros :